The AI Operator Onboarding Playbook: From Deploy to Autonomous
A week-by-week playbook for onboarding AI operators into your team. Shadow mode through autonomous operation, building team trust, and avoiding the common failure modes.
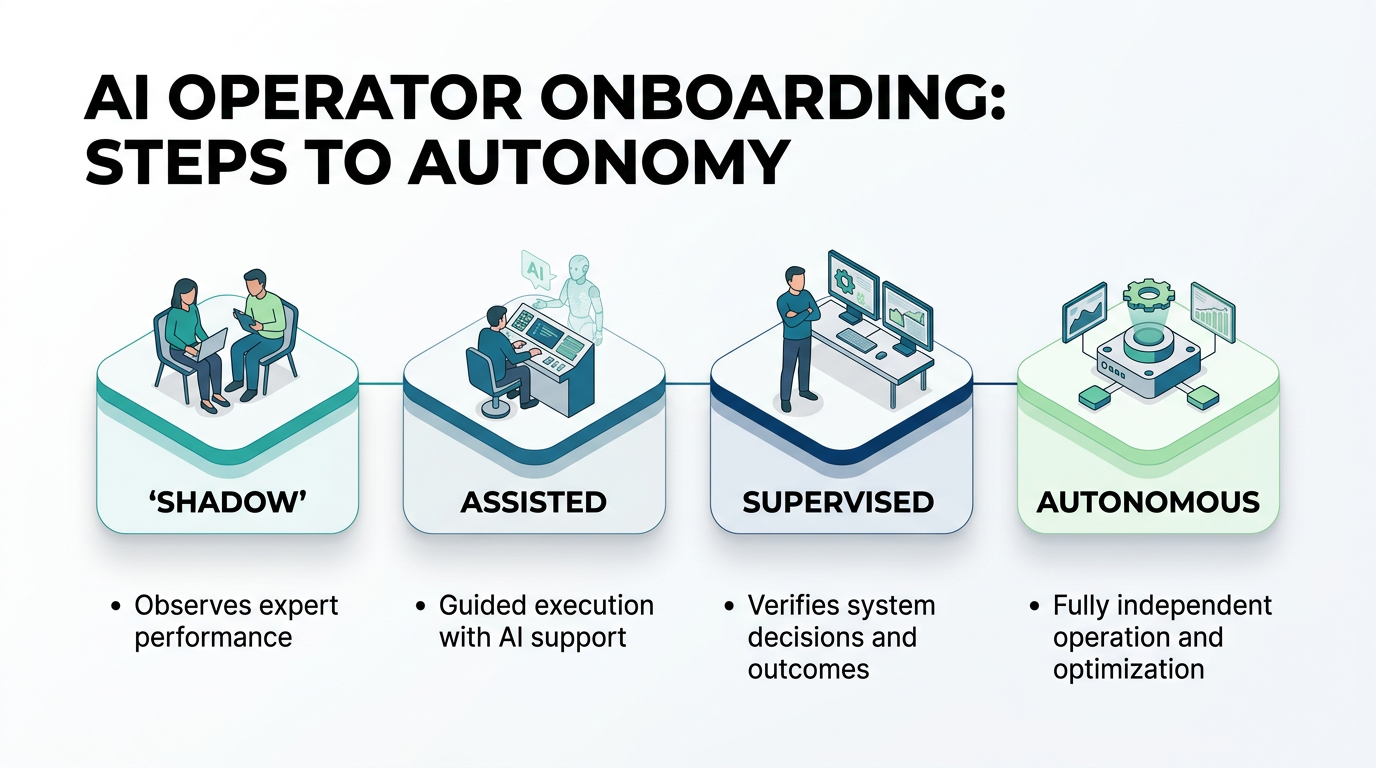
You've bought (or built) an AI operator. Congratulations. Now comes the part that actually determines whether it succeeds or fails: onboarding.
We've watched dozens of AI deployments. The ones that fail almost never fail because of the technology. They fail because of the rollout. The operator gets dumped into production too fast, the team doesn't trust it, edge cases aren't caught early, and six weeks later everyone agrees that "AI isn't ready for us."
It was ready. The onboarding wasn't. Here's the playbook we use to onboard AI operators, refined across every deployment we've done.
Before You Start: The Pre-Deploy Checklist
Before the operator touches a single piece of production data, complete this checklist.
Define success metrics. Write down exactly how you'll measure whether this deployment is working. Not vibes. Numbers. "Process 80% of tier-1 tickets without escalation, maintain 95% accuracy, reduce average response time by 50%."
Identify the human counterpart. Every AI operator needs a human sponsor on the team. This person reviews the operator's outputs, provides feedback, and serves as the escalation point. Choose someone who's organized, patient, and open-minded about AI.
Document the current process. Before the AI takes over, document how humans currently do the work. Every step, every decision point, every exception. This becomes the training material for the operator and the baseline for measuring improvement.
Set up the feedback loop. Create a simple mechanism for the team to flag operator mistakes. A shared Slack channel, a form, a tagged ticket category. Whatever works for your team. Make it frictionless.
Communicate to the team. Tell people what's happening before the operator shows up. Explain what it will do, what it won't do, and how it affects their work. Answer questions honestly. "It's not replacing anyone" is only effective if it's true.
Week 1: Shadow Mode
Objective: Validate that the operator understands the work.
In shadow mode, the operator processes every input and generates recommended actions, but nothing goes live. A human reviews everything.
Daily Routine
Morning: Review overnight outputs. The operator processed all incoming work and generated responses or actions. Check them against what the team would have done.
Midday: Flag discrepancies. When the operator's recommendation differs from what a human would do, categorize the gap. Is it a misunderstanding of policy? A missing piece of context? An edge case? Or is the operator actually right and the human process is inconsistent?
End of day: Log accuracy. Track the percentage of outputs that were correct, partially correct, or wrong. Log specific failure patterns.
What to Watch For
- Pattern accuracy. Is the operator handling the common cases correctly? If routine work isn't right in week 1, there's a configuration problem.
- Edge case behavior. When the operator encounters something unusual, does it escalate appropriately or try to handle it (incorrectly)?
- Consistency. Does it handle similar inputs similarly, or do you see random variation?
- Tone and style. If the operator generates customer-facing content, does it match your brand voice?
Expected Metrics
Week 1 accuracy should be 75-85% for a well-configured operator. Below 75% suggests the role definition needs work. Above 85% means you might be able to accelerate the timeline.
Common Failure: Skipping Shadow Mode
Some teams skip shadow mode because they're impatient or because the initial results look good. Don't. Shadow mode catches problems that testing can't. Production data is messy, inconsistent, and full of edge cases that synthetic test data doesn't cover. One week of shadow mode prevents weeks of cleanup later.
Week 2: Assisted Mode
Objective: Let the operator handle routine work independently while humans review complex cases.
Transition Criteria
Move to assisted mode only if week 1 accuracy exceeded 80% on routine tasks and the team is comfortable with the operator's output quality.
How It Works
Define explicit rules for what the operator handles independently vs. what gets human review:
- Auto-handle: Tasks that match well-defined patterns with low risk. Password resets, status inquiries, standard data entry, routine acknowledgments.
- Human review: Anything involving judgment, high-value transactions, unusual patterns, or customer escalations.
The split should be roughly 40-60% auto-handle in week 2. The goal isn't to maximize automation yet. It's to build confidence.
Daily Routine
Morning: Review the auto-handled work from overnight. Spot-check a random sample (20-30%) for quality.
Midday: Review the flagged items. Handle them, but note whether the operator's escalation decision was correct. You want the operator escalating the right things and handling the right things.
End of day: Update metrics. Track auto-handle accuracy, escalation accuracy (did it escalate things that needed escalating?), and any customer or stakeholder feedback.
Team Integration
This is where human dynamics matter. The team will have opinions about the operator. Some people will trust it too quickly. Others won't trust it at all. Both reactions are problems.
For the over-trusters: Remind them that assisted mode still requires review. Rubber-stamping the operator's outputs defeats the purpose.
For the skeptics: Show them the data. "The operator handled 47 tickets yesterday with 94% accuracy and caught 3 edge cases the previous system missed." Data converts skeptics faster than arguments.
Common Failure: Fuzzy Boundaries
"Use your judgment to decide what the operator handles" is not a boundary. Boundaries need to be explicit and machine-enforceable. If a human has to decide whether the operator should handle each case, you haven't gained anything.
Week 3: Supervised Mode
Objective: Expand the operator's scope and reduce review frequency.
Transition Criteria
Move to supervised mode if week 2 auto-handle accuracy exceeded 90% and escalation accuracy exceeded 85%.
What Changes
- Auto-handle percentage increases to 60-75%
- Human review shifts from spot-checking every batch to reviewing a daily sample (10-15%)
- The operator takes on additional task categories based on week 2 performance
- Escalation thresholds are refined based on actual patterns
The Trust Checkpoint
Week 3 is when you should have a formal review with all stakeholders. Present the data:
- Accuracy trends over three weeks
- Volume handled vs. human baseline
- Error types and severity
- Cost comparison
- Team feedback
If the numbers look good, plan the expansion for week 4. If there are concerns, extend supervised mode and address the gaps before proceeding.
Common Failure: No Formal Review
Teams that skip the week 3 review often end up in one of two states: the operator quietly accumulates more autonomy than intended (scope creep), or a single mistake causes the team to lose confidence and revert to shadow mode. The formal review prevents both by making the decision explicit and data-driven.
Week 4: Autonomous Mode
Objective: The operator owns the function. Humans monitor metrics and handle exceptions.
Transition Criteria
Move to autonomous mode if supervised mode accuracy exceeded 93%, no severity-1 errors occurred, and stakeholders approved the transition.
What Changes
- The operator handles 80-90% of work independently
- Human involvement is limited to exception handling and periodic audits
- Monitoring shifts from daily review to dashboard-based alerts
- The human counterpart's role changes from reviewer to supervisor
Setting Up Monitoring
Autonomous doesn't mean unmonitored. Set up alerts for:
- Accuracy drops. If the daily accuracy falls below a threshold, alert the team.
- Volume anomalies. Sudden spikes or drops in work volume might indicate a problem.
- New patterns. If the operator starts escalating a new category of issues, investigate.
- Sentiment shifts. If customer satisfaction scores change, review whether the operator is the cause.
The Monthly Review
Even in autonomous mode, conduct monthly reviews. Check metrics, review a sample of outputs, and assess whether the operator's scope should expand, contract, or stay the same.
Failure Modes and How to Avoid Them
Failure Mode 1: The Premature Promotion
Jumping from shadow to autonomous in a week because "it looks great." Every AI system looks great on easy cases. The hard cases take time to surface.
Fix: Follow the timeline. Four weeks minimum. Extend if the data warrants it.
Failure Mode 2: The Silent Degradation
The operator works well for months, then slowly degrades. Nobody notices because nobody's checking.
Fix: Automated monitoring with alerts. Monthly reviews. Don't let "it's working fine" become an assumption rather than a measurement.
Failure Mode 3: The Team Revolt
The team hates the operator because they weren't consulted, weren't trained, or feel threatened by it.
Fix: Communication before deployment. Involvement during onboarding. Transparency about what the operator does and doesn't replace.
Failure Mode 4: The Scope Monster
The operator keeps getting new responsibilities without additional evaluation or guardrails. It eventually handles something it shouldn't, and the resulting incident damages trust in the entire AI program.
Fix: Every scope expansion goes through a mini-evaluation. No exceptions.
The Long Game
A well-onboarded AI operator gets better over time. As it processes more cases, you refine its instructions, expand its capabilities, and tighten its guardrails. The month-one version is the worst version it will ever be.
But that trajectory only holds if you invest in the onboarding. Shortcuts in week 1 become crises in month 3. The teams that do this well treat onboarding as a four-week investment that pays dividends for years.
At OpFleet, onboarding is built into every operator deployment. We manage the shadow-to-autonomous transition, set up the monitoring, and handle the ongoing refinement. Your team gets a fully autonomous operator without managing the ramp.
Ready to onboard your first operator? We'll guide the process →